Conceptual Complexity Graph
Project information
- Category: NLP, Network Graph, Visualizations, Database
- Languages/Libraries/Tools Used: Python, Neo4j, NLTK, SpaCy, pandas, MongoDB, Dash, Dash-Cytoscape, BeautifulSoup, Requests/APIs, msgspec...
- GitHub URL: github.com/yannguerin/Conceptual-Complexity-Project
Overview
With this project I wanted to analyze the graph relationships between words and the words in their definition. My hypothesis is that a measure of complexity can be calculated from these relationships, with the use of graph algorithms, and that a structure would emerge through visualizing the graph. Uses a Neo4j database to manage my data and analyze the results, Dash-Cytoscape to visualize the graphs, and Dash to make the whole process interactive.
Current Progress
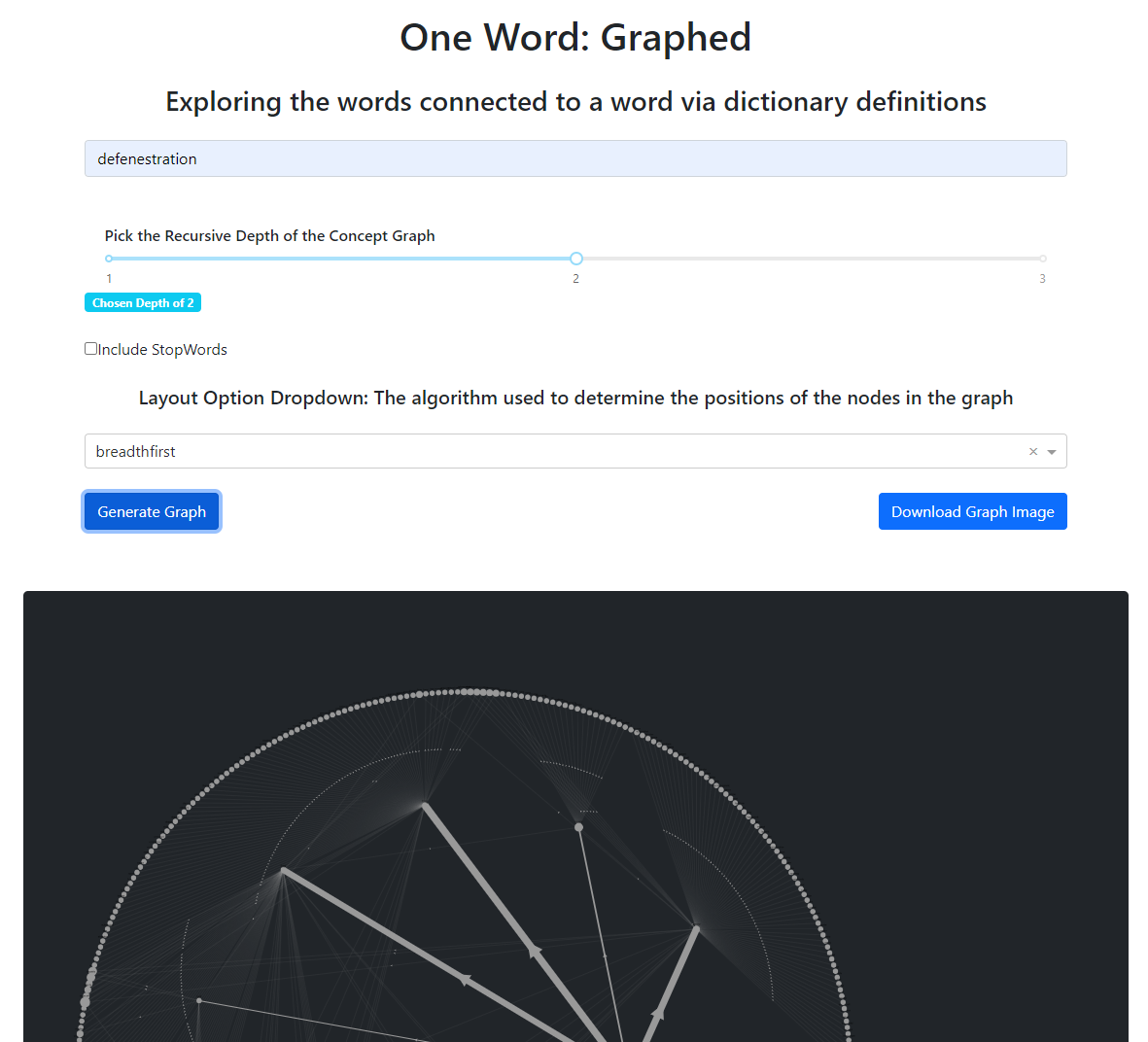
I started by scraping the entire Merriam Webster Dictionary, and storing all the documents into MongoDB. From there, I converted the semi-structured JSON-like documents into graph data representing a Word, and the Word-In-Definition. This converted over 250,000 words into 10 million rows of graph data. I then imported this graph data into a self-managed Neo4j Database, and began playing around with various queries. With the use a variable path length queries in Cypher I was able to extract all the words connected to a starting word within a certain path length.
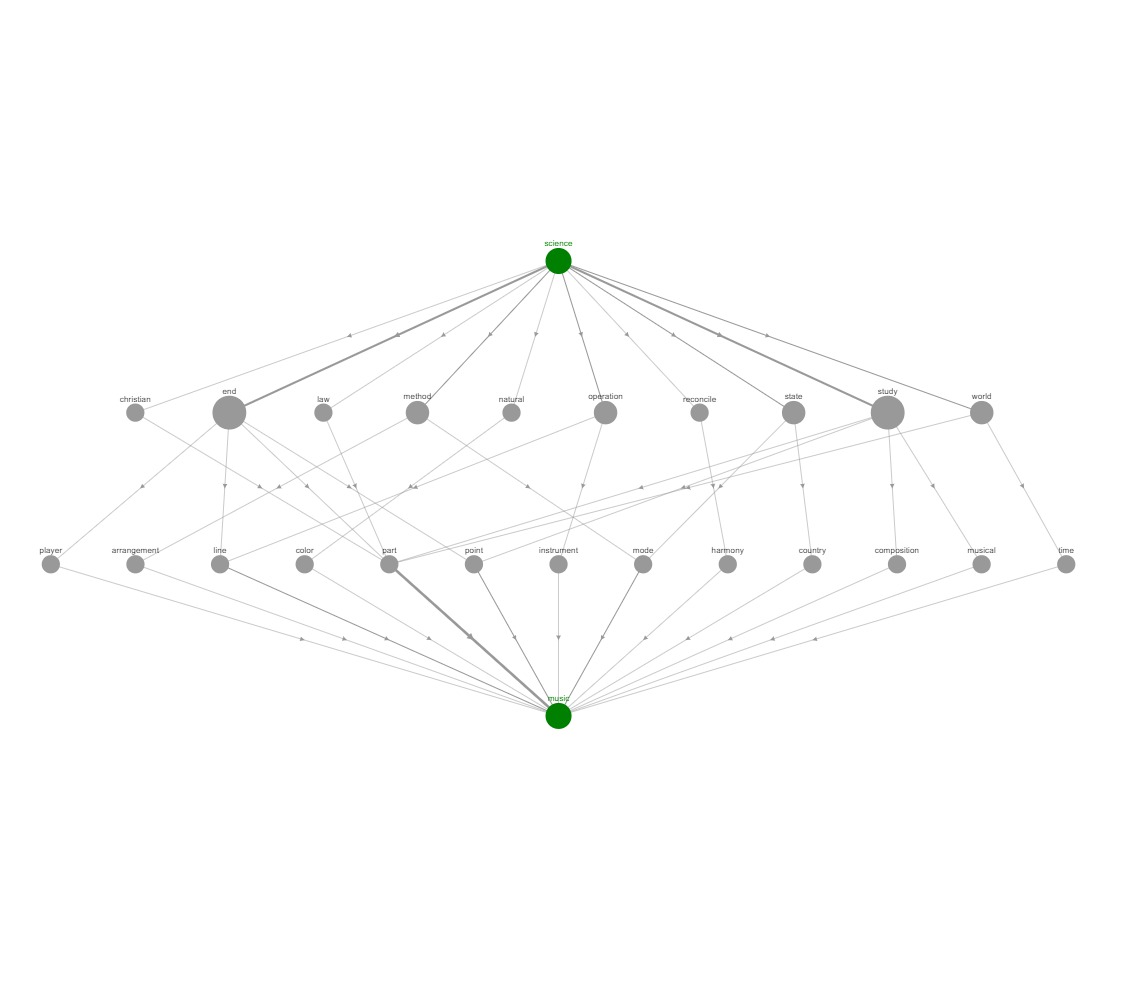
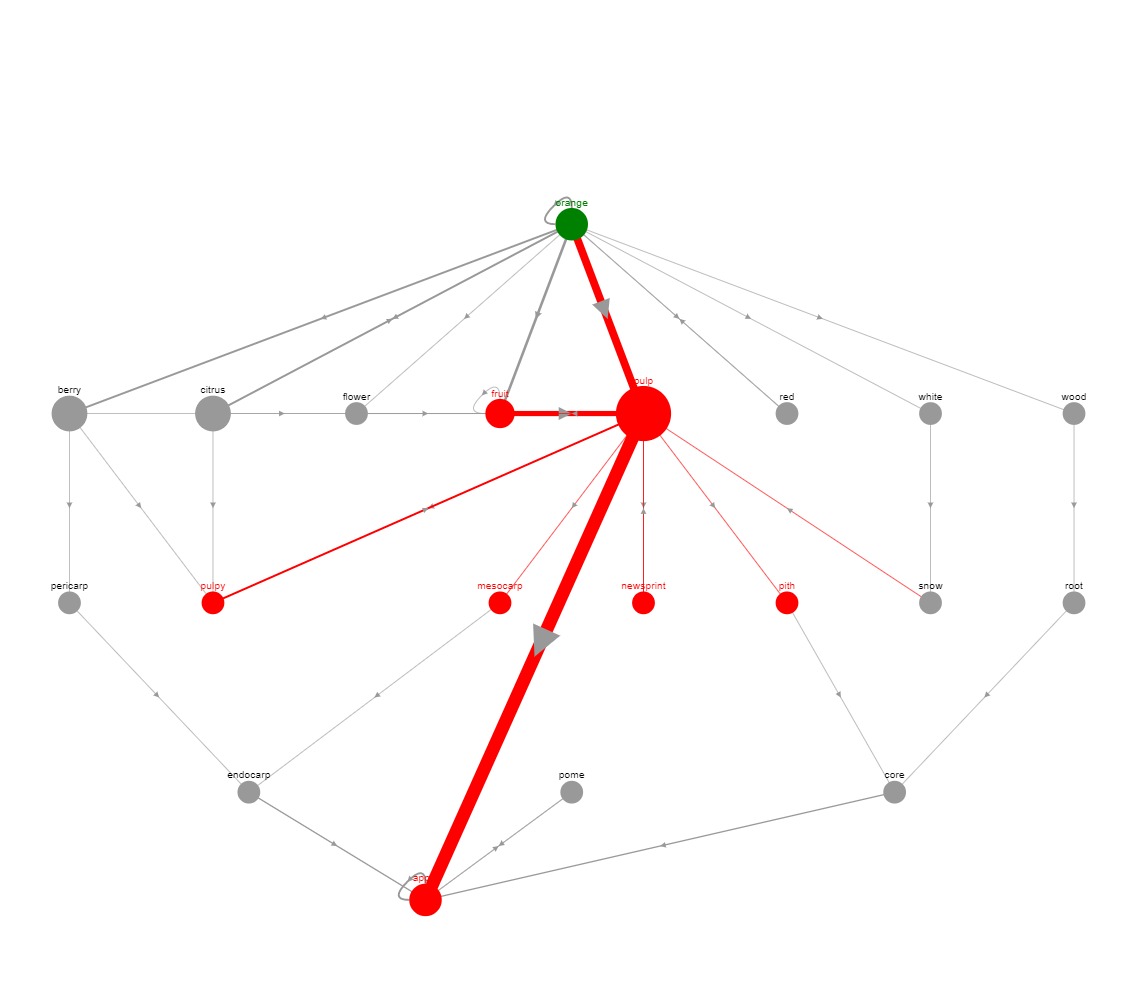
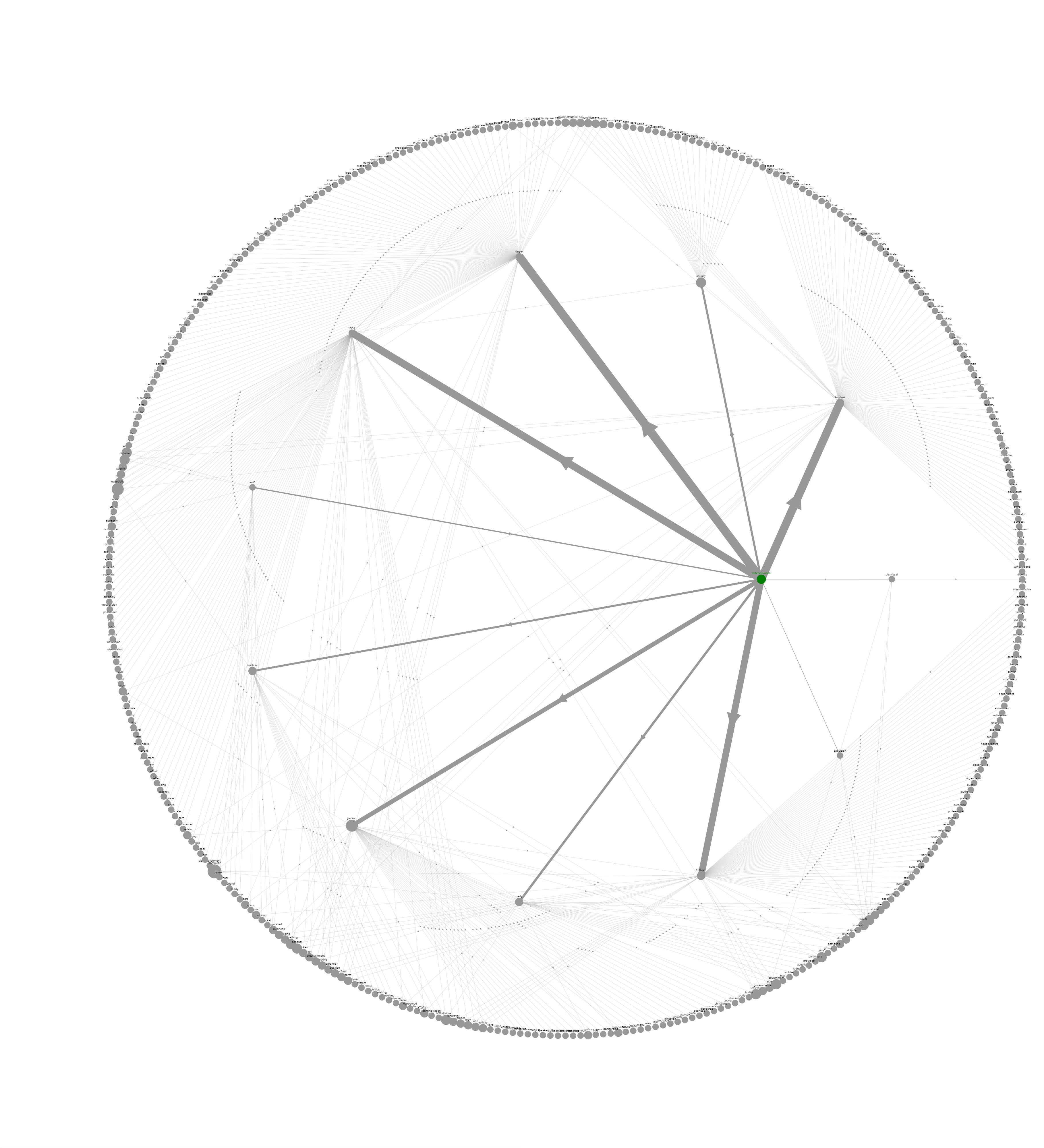
I used Dash, and Dash Cytoscape to visualize the graph data in an interactive web app. The web app allows the user to choose a starting word, a max path length, and select one of the graph layout options to then generate the graph. The generated graph has interactive features that allow the user to move around the nodes and click on nodes to highlight their connections to other words. The graph also changes the size of the nodes (based on how many connections they have), and the width of the edges (based on the number of times that relationship showed up in the query result).
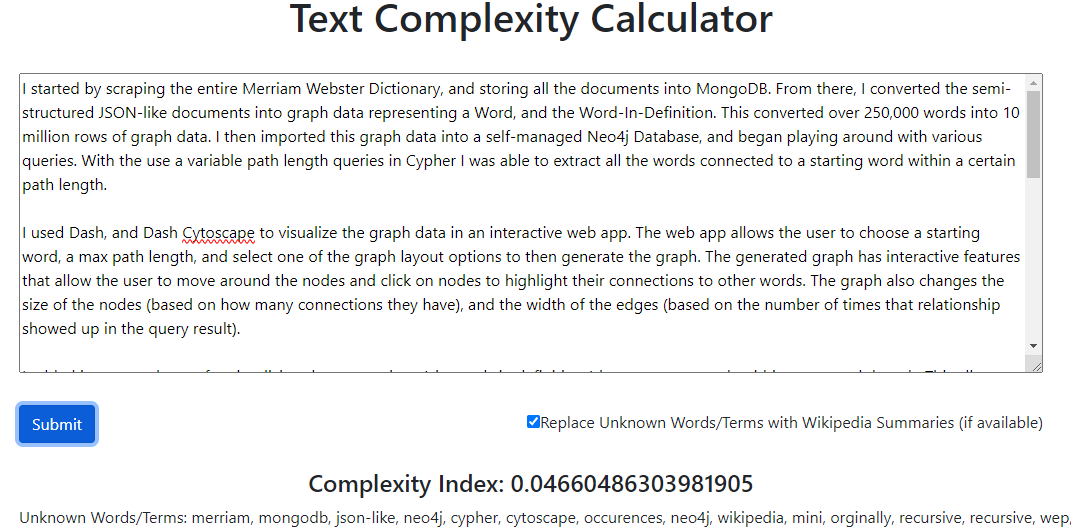
I added in a second page for visualizing the connections (via words in definitions) between two words within a max path length. This allows the user to see what word/terms connect two seemingly unconnected words/terms. I also added a third page that calculates the complexity of a given text returning a value between 0 and 1 (0 for simple, 1 for complex). This index of complexity is currently calculated using a simple approach of taking the average of the inverse of the number of occurences of the each word in dictionary definitions. This simple approach yields decent results; the indexes of various pieces of texts are very frequently ordered in the same way I would (subjectively) order them. Further testing of the algorithm on standardized pieces of text (from a curriculum for example) and further exploration of the graph algorithms and procedures within Neo4j will give me new ideas to improve the algorithm. Lastly, I added an extra feature to the complexity index to handle unknown terms (terms that aren't in the dictionary). I did this by allowing the user to allow the app to search Wikipedia for unknown words/terms and use the words in their summary (if found) as a replacement for the word/term itself.
When I built my first mini prototype of this project, the whole process of getting the data (orginally from an API), parsing and converting the data into graph data, and visualizing the data, all took nearly a whole minute to run even on recursive depths of 3. This was an unacceptable amount of time for me so I have spent a lot of time learning, reading, and applying what I have learned in order to drastically reduce the time it takes to visualize a word graph. Currently, for a path-length (recursive depth) of 3, the whole process runs in around 3 seconds - and produces an interactive graph versus a simple image.
I hope to have this Wep App be accessible to everyone, and to integrate it into this website, however there are some issues and costs associated with that. Currently, my Neo4j Database is self-managed, which means it runs on my computer. There are two options for hosting it on the cloud, the free tier or the paid tier. The free tier only allows me to have 200,000 nodes, and 400,000 relationships - this database currently contains 10 million relationships. The paid tier costs $65 USD per month, which is above what I am currently willing to pay for hosting this. The only other option is running my own server on a personal computer that provides access to the database, a feasible option, but one I do not possess the skills nor confidence to make reliable nor secure. If you would like to explore and interact with the project I would be more than happy to meet up with you in-person and bring my laptop along for you to try it out.
Future Development Goals
I will continue to read, and learn about the capabilities of Neo4j and the algorithms and procedures available. I have seen quite a few interesting ones that I would like to try, and that I hope will yield interesting, useful results. I also plan on adding more interactive features to the Dash Web App, from improved layout options, visualizing connections between n-words, and much more. I would also like to make some additions/improvements to the dictionary data, from improving the initial parsing of the definitions, to including bigrams in the words-in-definition column, to exploring other data sources, I believe improvements to the data could produce better results. I have lots more work I would like to get done on this project, and a bunch of ideas to try out.